
시계열 데이터베이스 사용하기
1. InfluxDB 준비하기

0. 시계열 데이터베이스 (Time Series Database)를 왜 사용할까?
회사에서 데이터베이스를 이용해서 데이터를 저장하면 많은 경우 이 데이터를 시간의 흐름에 따른 현상을 파악하기 위한 리포트나 Dashboard 형태로 사용한다는 것을 알게 된다. 예를 들어, 월별 판매랑, 평균 판매량, 일별 장애 건수, 서비스 사용 시간, 시간별 자원 사용량 등 많은 경우 시간과의 관계를 파악하려고 데이터를 사용한다. 이렇게 시간과 관련된 데이터분석, 즉 기간 내 최고, 최저, 합, 평균, 분산 등을 구할 때, 기존의 RDB보다 빠르게 얻을 수 있도록 만들어진 데이터베이스가 시계열 데이터베이스(Time Seris Database)이다.
시계열 데이터베이스(Time Series DB)와 관계형 데이터베이스(Relational DB)의 성능상 차이점은,
- 시계열 데이터베이스는 LSM tree를 사용하여 데이터를 저장하기 때문에 먼저 메모리 영역에 write 하고 나서 한 번에 모아 디스크 영역으로 write 하기 때문에 쓰기 성능(write performance)이 뛰어나다.
- 관계형 데이터베이스는 적절히 밸런스 된 B+tree를 index로 사용하므로 하나의 key를 insert 하기 위해 worst case에서 모든 레벨(B tree의 높이)에 write를 하기 때문에 상대적으로 쓰기 성능(write performance)은 떨어진다.
- 시계열 데이터베이스는 시간의 순으로 디스크에 정렬되어 있기 때문에 시간에 대한 연산, transformation, aggregation에서 관계형 데이터베이스 보다 좋은 성능을 나타낸다.
- 관계형 데이터베이스는 필요한 key마다 index를 정의하고 B tree로 관리하기 때문에 임의의 관계로 연결된 데이터들의 조합을 뽑아낼 때에는 시계열 데이터베이스 보다 빠르다.
하지만, 시계열 데이터베이스는 데이터를 저장하고 처리하기 위한 표준적인 방법(SQL)이 정해지지 않은 NoSQL이다. 따라서, 데이터베이스를 정의하는 스키마(Schema)도 제품마다 다르고, 데이터베이스에 사용하는 방법도 제품마다 다르기 때문에, 한번 업무에 도입이 되면 다시 바꾸기 위해 많은 노력이 필요하기 때문에 신중하게 선택해야 한다.
많이 사용되고 있는 시계열 데이터베이스에는 Hadoop을 기반으로 한 TSDB, 시스템 모니터링에 많이 사용되어 인기가 있는 InfluxDB, 상용으로 최근에 점유율을 확대하고 있는 kdb+나 machbase 등 많은 제품이 있는데, 나는
- 내 컴퓨터에 무료로, 쉽게 설치할 수 있고,
- 적은 노력으로 사용할 수 있는 Library 또는 데이터 수집 프로그램이 있고,
- 사용하고 있는 사용자가 많아 쉽게 정보를 구할 수 있고
- 실 환경에 적용할 때 기술 지원을 받거나
- 필요하면 좀 더 관리가 쉬운 클라우드도 사용할 수 있는
influxDB를 사용해서 시계열 모니터링 정보를 저장해 보기로 했다.
1. influxDB 준비하기
influxDB는 grafana와 함께 모니터링 시스템을 쉽게 만들 수 있어 많은 사람들이 사용하게 되었다. 나도 이전에 근무하던 대기업에서 인프라 운영에 필요한 모니터링 시스템을 만들 때 influxDB와 grafana를 사용해 만든 것이 있다. 이번에 확인해 보니 grafana도 그동안 많이 발전해서 처음 나왔을 때와는 달리 여러 서버를 연결할 수 있는 backend server도 개발되었고, influxDB뿐 아니라 datadog, mongodb, oracle 등 다양한 데이터베이스를 저장소로 지정할 수도 있고, docker, mysql, kafka, rabbitmq 등 다양한 서버와 연결할 수 있게 발전된 것 같다. influxDB 역시 자체 데이터 수집 프로그램인 telegraf를 사용하여 더 많은 시스템으로부터 모니터링 정보를 수집할 수 있도록 발전하고 있다.
가. Docker로 influxDB실행하기
influxDB를 내 윈도우 노트북에서 쉽게 설치하고 테스트해 보기 위해서는 docker를 사용하는 방법이 가장 편리하다.
만일 docker가 설치되어 있지 않으면 docker를 설치한다.
윈도우에 만드는 리눅스 개발 환경; 2. 윈도우에 Docker 설치
윈도우에 만드는 리눅스 개발 환경 목차 1. 우분투 리눅스 설치 (윈도우 10) 2. 윈도우에 Docker 설치 3. nvm으로 node.js 설치 4. VScode 설치 5. Docker로 MySQL시작하기 6. Docker로 MongoDB 시작하기 7. 윈도우 11
front-it.tistory.com
먼저, 아래와 같이 -p로 옵션으로 포트를 열고 -v 옵션으로 내부와 연결할 공간(volume)을 할당하고 influxdb 컨테이너를 만들어서 실행한 다음,
docker run -d --name=influxdb -p 8086:8086 -v "e:\works\influxdb\:/var/lib/influxdb2" influxdb:latest
만일 docker로 telegraft를 실행하고 telegraf docker와 연결하기 위해 내부망을 구성하고 싶다면, docker bridge를 만들고
$ docker network create --driver bridge telegraf-net
docker run명령을 실행할 때 아래와 같이 -net옵션을 추가하면 된다.
--net=telegraf-net
하지만, 나는 내 노트북에 telegraf를 설치하고 노트북의 System정보를 수집하는 테스트를 할 예정이기 때문에 따로 bridge를 만들지 않았다.
초기 설정을 위해 다음과 같이 docker에 연결하고 setup을 호출하거나,
docker exec -it influxdb influx setup
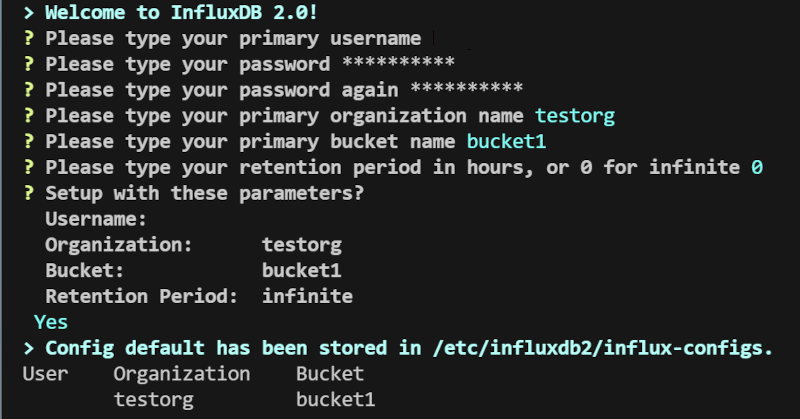
influxdb관리 웹페이지
http://localhost:8086
를 접속해서 초기화를 진행한다.
influxDB에서 Bucket은 관계형 데이터베이스의 database에 해당한다고 보면 된다. 나는 테스트용으로 bucket1이라고 만들어 봤다. Retention Period는 관계형 데이터베이스에서 보지 못했던 부분인데, 시계열 데이터를 얼마기간 동안 보관할 것인지를 묻는 것인데, 이 기간이 지난 데이터를 자동으로 삭제해 준다. 0을 넣으면 지우지 않는다(infinite).
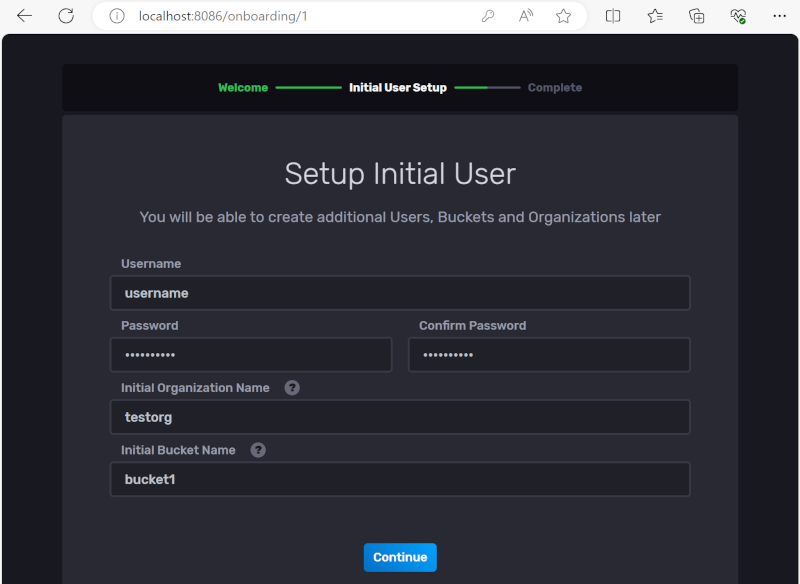
초기 설정을 완료하고 나면 내 컴퓨터의 influxDB에 접속할 수 있게 된다.
http://localhost:8086
나 telegraf로 모니터링 데이터 수집하기
influxDB를 실행했으니, 복잡한 업무를 적용하기 전에 내 컴퓨터의 cpu, disk, mem, 등의 system정보를 influxDB에 넣어 한번 사용해 보기로 했다.
- telegraf로 데이터를 넣기 위해 "Load your data"를 선택한다.

- "Load Data"화면에서 "Telegraf"를 선택한다.
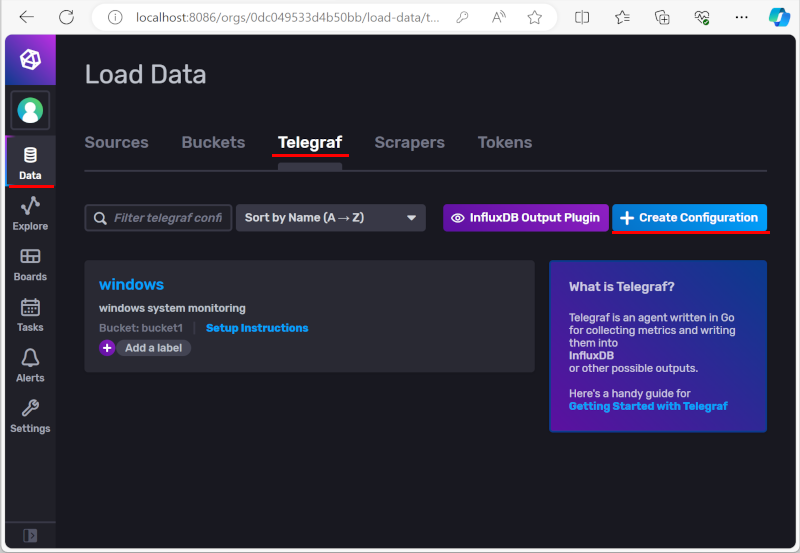
Telegraf는 input plugin을 사용해서 data를 수집하고 output plugin을 통해 수집된 data를 기록하는 데이터 수집 프로그램인데, telegraf를 실행하려면 configuration파일이 필요하다. telegraf configuration은 influxDB페이지에서 wizard방식으로 쉽게 만들 수 있다.
- Bucket은 influxDB를 초기화할 때 만든 bucket명(내 경우는 bucket1)으로 선택하고 System을 선택한다
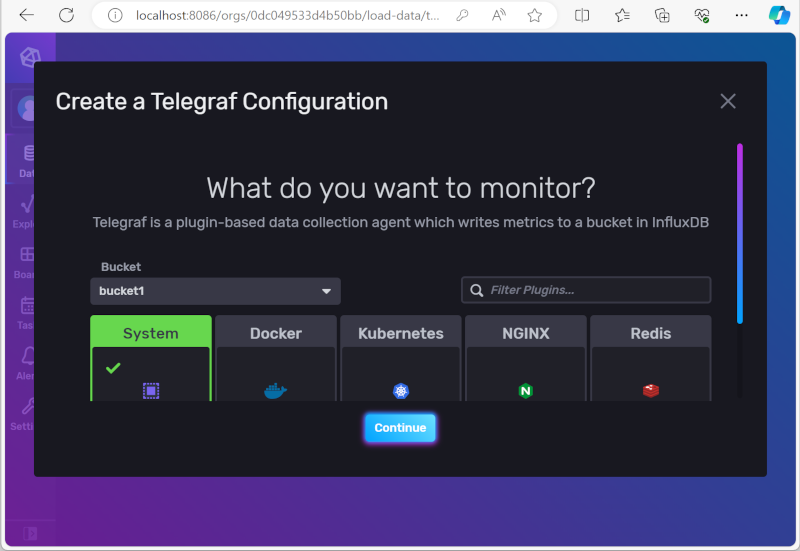
- "Telegraf Configuration Name"에 마음에 드는 이름을 넣고 "Create and Verify"를 선택하면

- 나오는 마지막 화면의 지시에 따라 Telegraf를 다운로드하고 Telegraf를 실행한다.

마지막 화면의 지시에 따라
1. 먼저 Telegraf를 다운로드한다.
curl.exe https://dl.influxdata.com/telegraf/releases/telegraf-1.29.4_windows_amd64.zip --output telegraf-1.29.4.zip
이 curl 명령어는 이 문서를 만들 당시 버전 telegraf-1.29.4이 기준이고, 최신 버전은 아래 링크를 사용해서 받는다.
InfluxData Downloads
Register your download Get access to the new InfluxDB Open Source Software Onboarding Guide, product updates, and free InfluxDB stickers!
www.influxdata.com
압축을 풀면 telegraf.exe파일과 telegraf.conf파일이 생기는데, 이 telegraf.conf를 사용하지는 않는다.
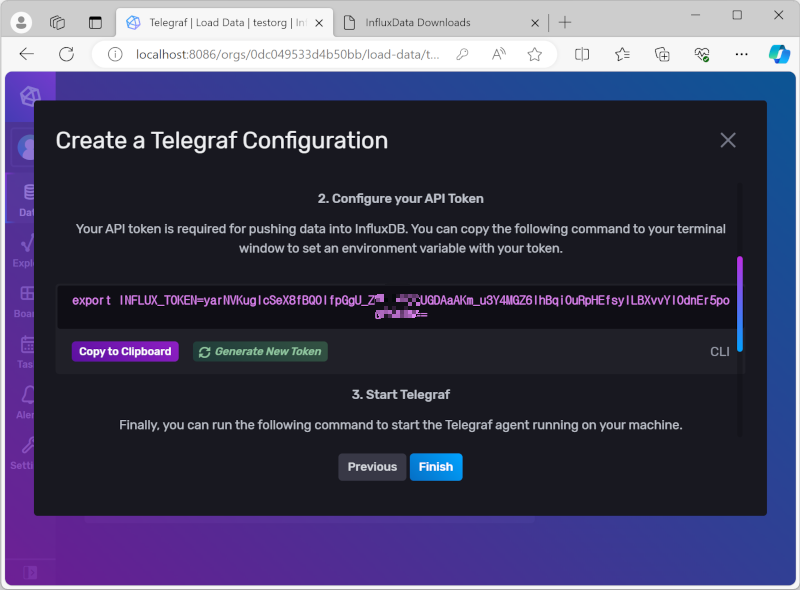
2. 이제 터미널을 열고 화면에 표시된 API Token을 환경변수에 설정하고 (윈도우 CMD의 경우 SET을 사용한다.)
export INFLUX_TOKEN=yarNVKugIcSeX8fBQOIfpGgU_Z-----GDAaAKm_u3Y4MGZ6IhBqiOuRpHEfsylLBXvvYIOdnEr5po----
SET INFLUX_TOKEN=yarNVKugIcSeX8fBQOIfpGgU_Z-----GDAaAKm_u3Y4MGZ6IhBqiOuRpHEfsylLBXvvYIOdnEr5po----
3. 방금 생성해서 서버에 저장한 configuration파일을 사용해서 telegraf를 실행한다.
telegraf --config http://localhost:8086/api/v2/telegrafs/0c9c3ddc54343000

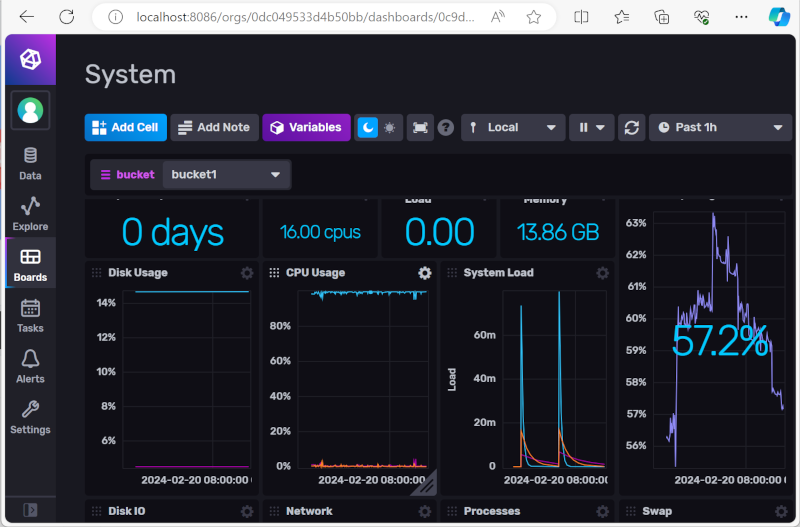
이제 "Launch for Data"를 누르면 InfluxDB로 Telegraf에서 data가 들어가기 시작한다.

감시 기다리면 데이터가 들어가고 있는 것을 외쪽의 "board"메뉴를 누르고 방금 만든 "System"을 누르면 화면을 통해 확인할 수 있다.
마지막으로, Telegraf에서 지원하는 더 많은 Plugin에 대해 알고 싶다면 다음 링크를 참고하면 된다.
Plugin directory | Telegraf Documentation
Thank you for your feedback! Let us know what we can do better:
docs.influxdata.com
'윈도우 개발환경' 카테고리의 다른 글
| 시계열 데이터베이스 사용하기; 2. InfluxDB 이용한 모니터링 대시보드 (1) | 2024.03.26 |
|---|---|
| 쿠버네티스로 MSA DevOps 환경 구축; 2. 로컬 컨테이너 Registry (0) | 2024.02.23 |
| 쿠버네티스로 MSA DevOps 환경 구축; 1. 로컬 쿠버네티스 설치 (0) | 2024.02.15 |
| 윈도우에 만드는 리눅스 개발 환경; 8. Docker로 PostgreSQL 시작하기 (0) | 2023.12.28 |
| Flutter 개발 환경 만들기; 1. 안드로이드 App (1) | 2023.12.18 |



